Read-Copy Update — or — Living Lock- and Wait-Free with RCU
Modern CPU architectures reward parallel / concurrent programs with higher throughput. Gone are the days of writing single-threaded, serially executed code — it just doesn't scale. As chip vendors pack more and more logical cores onto the silicon, this performance gap widens.
Threading to the rescue! Parallelize your solution, spin up a bunch of concurrent threads, and go. If only it were that simple. Too bad there's data.
Data ruins everything. TV. The word “big”. Dating. Political debates. Naïve parallelization of innately serial algorithms.
The problem with data is that we have to use it, often from multiple concurrent threads, without introducing TOCTOU (Time of Check, Time of Use) problems or other race conditions.
So our program grows some mutex (mut-ual ex-clusion) locks. Whenever a thread wants to read or write to a shared bit of data, it must acquire the lock. Since only one thread can hold the lock at any given time, we're golden. The program is correct and everyone is happy.
Except that the performance suffers.
This is a classic trade-off in computer science. Go fast / be safe. Pick one. Or, to put it in Firefly terms: you can increase speed if you run without core containment, but that's tantamount to suicide. Boo-yah. Firefly reference.
Back to our performance problem. The root cause of observed slowdown is the bottleneck caused by the mutex lock. By definition, the mutex lock serializes parts of the program, which introduces bottlenecks. Readers can't read while a writer is writing. But readers can totally read while other readers are reading. The next evolution of the program introduces reader/writer locks.
Reader/writer locks split the locking activity into two parts. A write lock works like our previous lock - only one thread can hold the write lock at any single instant. The read lock, on the other hand, (a) can be held as long as no one has the write lock, (b) can be held by multiple readers concurrently and (c) precludes any thread from obtaining the write lock.
The upshot of this new approach is that reader threads are not held back by other readers (a situation called starvation), but we still don't introduce any data race conditions because all reads will be serialized with any writes.
For read-heavy workloads, the optimization usually ends at the reader-writer lock step. Improving the throughput of writes rarely improves performance since the bulk of the work revolves around reads. For other workloads, including write-heavy and split read/write, optimizing writes is essential.
Enter Read-Copy Update, or RCU. A constrained form of multiversion concurrency control (MVCC for those TLA fans out there), RCU solves the scaling problem by trading convergence for availability (remember the CAP theorem?). The premise is simple: as long as readers get an consistent view of the shared data, does it really matter that they get the most up-to-date version?
Consider a linked list, that looks like this:

Under a locking strategy, inserting a new item would wait until there were no readers before going ahead with modifications. What if, instead, we could ensure that a reader got one list or the other, but not some weird in-between version? That is, a reader would see either:

or:

The kicker is that either scenario is perfectly valid.
Without getting into the nitty-gritty implementation details (that's a different post altogether), this is what RCU nets you: the ability to do updates with minimal serialization between readers.
In grossly oversimplified terms, RCU performs atomic modifications on a shared data structure such that any reader can traverse the data structure at any time, without getting a corrupted view. Let's return to our A → C → D list, with two reader threads traversing the list at different points.
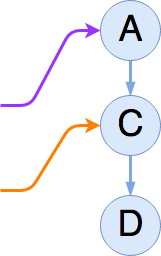
Without synchronizing with these two readers, an updater thread
can create a new list item, B, and half-splice it into the list by
linking its next pointer to C:
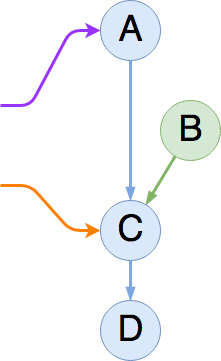
Nothing has changed for either reader. The first reader is still set to traverse A → C → D, and the second reader will finish traversing C → D (having already seen A).
The next step (which is also atomic) replaces the next pointer
of A with a pointer to B, thereby completing the insert operation:
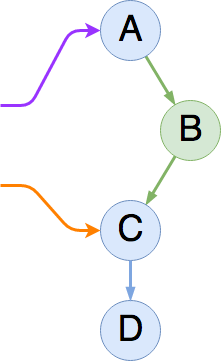
Now we've affected the readers. If the first reader is scheduled
after the atomic next-swap, it will traverse A → B → C → D.
If it gets scheduled before the swap, it will see A → C → D. No
matter what, the second reader is not affected by the operation,
and will see the entire list as A → C → D.
Removal is similar, except that the operations play out in reverse, and there's a small housekeeping task called reclamation or synchronization.
At this point in our example, we've completed our insertion operator, so the full list is A → B → C → D. The second reader has completed its traversal of the list (no orange arrow). The first reader has advanced to B (and become our new second arrow). We also now have a new reader starting at the head of the list (in green).
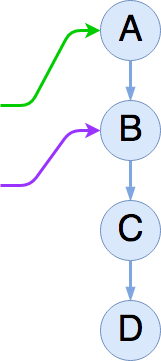
Let's remove B! The first thing we are going to do is re-link A
directly to C by (atomically) swapping its next pointer
appropriately:
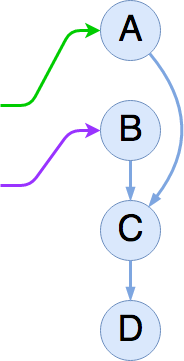
Now we can see the same “dual-state” phenomenon we saw before with insertion; the first reader will see the post-remove version of the list (A → C → D), while the second reader finishes out B → C → D having already seen A.
Assume that new readers will have to start at the head of the list (A) and proceed linearly — that is, no random access, and no pointer aliasing is allowed. If we can figure out when all existing readers have lost access to the deleted item B (we can), then we can free the list item and any associated memory.
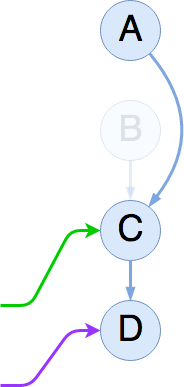
Depending on how you implement this, the writer thread can synchronize on the RCU-protected data structure, waiting for all readers to lose visibility into the data structure's interior, or the writer thread can defer that task to a reclamation thread that periodically synchronizes.
If you read through the last few paragraphs but couldn't help thinking “gee, this sounds a lot like garbage collection semantics,” you would be spot on.
Garbage collection is fundamentally about letting other parts of the system (namely, programmers) forget to clean up after themselves, by explicitly freeing resources that can no longer be reached.
RCU executes this reachability analysis through the use of read-side critical sections, quiescent states and grace periods.
A read-side critical section is a window in both time and code during which a reader may retain access to internals of the shared data. An RCU-aware list traversal algorithm enters its read-side critical section just before reading the head pointer, and exits after processing the last list item.
At any point during the critical section, we can't know precisely what part of the list is under observation (the first item? the last? who knows!). We do however know that mucking about with any part of the shared structure will lead to race conditions. We've traded accuracy for speed.
A quiescent state is (for readers) everywhere / everywhen that isn't a read-side critical section. When a thread enters a quiescent state, it is a guarantee that all previous operations on the shared data have completed, and it is therefore safe to go mucking about with the internals.
Closely related to quiescent states are grace periods. A grace period starts the moment we perform a destructive operation, and ends once each thread has been in a quiescent state at least once. At that point, it is provably safe to reclaim garbage.
In a picture:
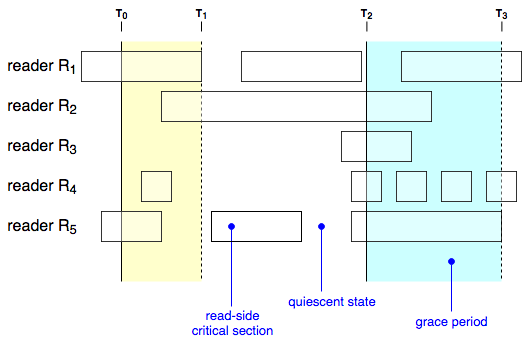
We have five readers (\(R_1\) – \(R_5\)), each accessing a shared data structure via RCU semantics. Time proceeds from left to right.
At \(T_0\), an update operation is initiated, and a grace period begins. Readers \(R_1\) and \(R_5\) are concurrently in read-side critical sections, so each will have to enter a quiescent state before the grace period will end. At \(T_1\), reader \(R_1\) enters a quiescent state. Since \(R_5\) was already in a quiescent state, this ends the grace period.
Note that for the first grace period, neither \(R_2\), nor \(R_4\) have any bearing on the grace period. \(R_4\) ends before the grace period does, but both sections start after the destructive operation has been performed, so they are provably unable to see the removed node.
The second grace period, highlight in blue above, stretches from time \(T_2\) – \(T_3\). When it starts, all readers except for \(R_1\) are in read-side critical sections. By the time \(R_1\) enters its critical section, the change has been completed, and it has no effect on when the grace period ends.
In fact, only threads that are in critical sections when a grace period starts can prolong the grace period. However, once an “involved” thread enters a quiescent state, it no longer holds any power over the grace period. Intuitively, this makes sense; a thread in a quiescent state has (by definition) stopped interacting with the internals of the shared data, and cannot possibly hold copies of any internal pointers.
You can also see this principle at work by looking at the boxes in the diagram. Go ahead, I'll wait.
Do you see what \(R_4\) is doing? It is very quickly waffling from quiescent state back into a critical section. It manages to bounce back and forth three times before our slow \(R_5\) reader quiesces. But the last four of \(R_4\)'s critical sections have no bearing on the grace period.
There's a bunch of interesting math and bit twiddling tricks involved in implementing RCU on a real machine. I hope to get to those in my next post, which delves into the nuts and bolts of implementing RCU in a real-world C program.
Further Reading
The best (and most academic) paper I've found so far on RCU is User-Level Implementations of Read-Copy Update (14pp). The author list includes Paul McKenney — you'll see his name a lot in the literature. There's also supplemental material (12pp) available.
The second-best paper is Read-Copy Update (22pp). It's a lot less generic, and geared specifically towards implementation inside of an operating system kernel; namely, Linux. (It was published at the Ottawa Linux Symposium, in 2001).
For a more accessible, Linux-specific treatment, including how it is used, kernel calling conventions, etc., check out this three part series by the fine folks over at LWN.
If you're in for a longer read, or just really like the subject matter, Paul McKenney has written volumes. You may want to check out his dissertation (380pp), His book, Is Parallel Programming Hard, And, If So, What Can You Do About It? (477pp) discusses RCU and a wealth of other parallel programming topics (also forkable on Github).
And if you're really, really into it, here's some further, further reading. You've been warned, and if this costs you the next few weekends of your life, it's not my problem. ^_^
Happy Hacking!

James works on the Internet, spends his weekends developing new and interesting bits of software and his nights trying to make sense of research papers.
Currently exploring just how much data you can shove though DuckDB before it explodes.