A Troubleshooting Yarn — or — Pull Up A Seat, and I'll Weave You A Tale
So the other day, I started writing braid. It's an implementation of the HTTP RFCs (723x). You see, I want to write web APIs in C.
I know, I know, I should use a more modern language. Or a memory-safe language. Or some other such nonsense. I have been in this industry long enough, I shall do as I damn well please. Besides, GitHub is big enough for all of us.
I started in on the guts of RFC 7230, the message syntax, and banged out a parser with a sliding window buffer. It worked pretty well, and was quite flexible, if I do say so myself. The design hinges upon the idea of strands, the small bits of a string that we can read with only a small, fixed-size buffer to range over.
Consider a minimalist HTTP request:
GET /some/path HTTP/1.1⏎
Host: localhost⏎
Accept: */*⏎
⏎
That's less than a hundred bytes. It's super easy to parse, too: just read the whole thing into a 1k buffer and go to town.
But what happens if some jerk out on the internet sends you a request like this:
GET /some/path HTTP/1.1⏎
X-Evil: <10,000 "HA"'s in a row>
Host: localhost⏎
Accept: */*⏎
⏎
That's definitely not going to fit in our 1024-byte buffer. Or our 8192-byte buffer. Or a 64k buffer. At some point, if we keep making the buffer bigger, the world cranks out a bigger prankster trying to crash our software, looking for a laugh at best, or an RCE at worst.
What the braid parser does is keep track of a single strand, which contains the chunk of a string we've seen so far. When it runs out of buffer, but hasn't finished parsing a request, the parser measures off enough memory, copies out the parsed data, and appends it to the current strand.
It looks like this:
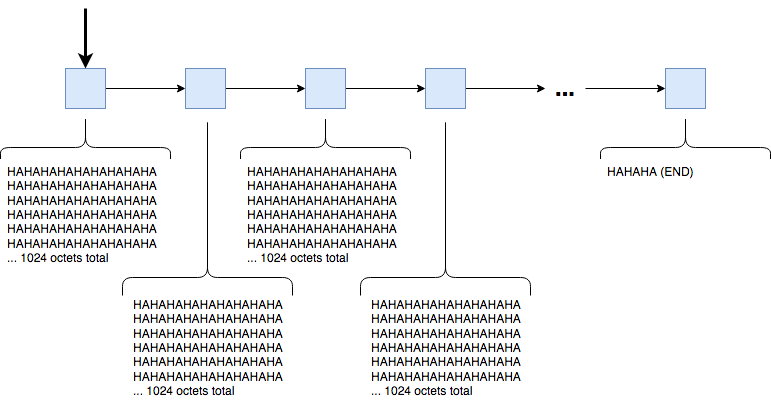
I wrote a small test-suite that exercised various edge cases for this stranding design, varying the length of the URI from 100 characters to 19,000 characters, and then doing the same for a header value, a header name, etc.
All Tests Passed.
A beautiful feeling. But this is an essay about troubleshooting, by gum,
and for that, you need trouble. My trouble started when I noticed the
off-by-one error that lead me to stop at 19,000 characters. One s/</<=/
later, and now my tests are failing.
They're not just failing. They're segfaulting.
Now I've been doing all of my development on my new MacBook 13", 2017 edition (without the Touch Bar thank you very much). Say what you will about developing software on macOS, but I'll say this: the debugging facilities outright suck. No Valgrind. No American Fuzzy Lop. GDB requires some crazy workarounds.
So I take a quick detour to a random Linux cloud host that I keep around because sometimes it beats a sharp stick in the eye. There, arrayed before me (heh) are all my beautiful debugging tools; implements of master craftsmanship.
So I fire up Valgrind.
valgrind ./msgtest </test-data/braid.test.cF9n4TI
... a bunch of boring stuff omitted; you're welcome ...
==24161== Invalid read of size 8
==24161== at 0x400B41: append (msg.c:129)
==24161== by 0x40163A: advance (msg.c:378)
==24161== by 0x401A62: main (msg.c:462)
==24161== Address 0x52043d0 is 4 bytes after a block of size 12 alloc'd
==24161== at 0x4C2DB8F: malloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==24161== by 0x400C60: append (msg.c:144)
==24161== by 0x401364: advance (msg.c:325)
==24161== by 0x401A62: main (msg.c:462)
==24161==
Okay, so that's bad. Apparently, my little test program is trying to tromp all over someone else's memory. This is an out-of-bounds memory access violation, which is just the kind of thing you expect Valgrind to find. Yay!
So now I just need to figure out who is setting the pointer to the errant
address. I tracked the problem down to the next pointer on the strand
implementation, and it only seems to manifest when we have to append the
second strand.
As I am a proud printf debuggerer, I found all the places in the
code where the next pointer is set, nullified, referenced, or even thought
about, and I put in copious amounts of printf("next: %p\n", x->next)
calls. Fire up Valgrind again. Get the same error about an invalid read, 4
bytes into another variable's back yard. Same address too! But...
But. But none of the printf statements ever printed the value being
accessed. That 0x52043d0 pointer address is literally only printed out
by Valgrind itself. And Valgrind has no bugs, so this is one hell of a
thinker.
Anyhow, it's time to go to my day job, so I switch off of that terminal tab and focus my mind on lesser demons like Go, and avoiding Slack, and tracking down people for pairing sessions.
The back of my head, however, can't stop working on this stupid problem.
0x52043d0 is slowly, maddeningly burning a hole into my brain.
Teasing me. Taunting me. Tormenting me.
... fast-forward 8-or-so hours ...
Back to this.
I need to look at memory. Clearly something went wrong somewhere, and some
pointer got munged. When you need to look at arbitrary memory locations,
you need GDB.
gdb ./msgtest
gdb> run <t/test-data/braid.test.cF9n4TI
... a bunch more boring stuff omitted; you're welcome ...
Program received signal SIGSEGV, Segmentation fault.
0x0000000000400b41 in append (st=0x604000, a=0x7fffffffdd10 'A' <repeats
200 times>..., b=0x7fffffffe110 "") at src/msg.c:129
129 fprintf(stderr, "ins->next->next=%p\n", ins->next->next);
Yup. That's a segfault. Looks like it's actually dying on one of my
printf()s. Time to look at this ins character (that's the insertion
point on the strand, if you're curious).
(gdb) print ins
$1 = (struct strand *) 0x604000
Right. A pointer. Gotta dereference it.
(gdb) print *ins
$2 = {len = 0, data = 0x31 <error: Cannot access memory at address
0x31>, next = 0xb}
Now that IS interesting. The next pointer is 0xb; not quite NULL
(that would be 0x0), but definitely not high enough to be an actual
pointer. Also, we have a data pointer of 0x31, which is also suspiciously
low in the address space, and a len of 0 (no bytes in the strand).
All of this points to some sort of memory corruption. But where? Valgrind
didn't indicate that anything else was off. These errors are all occurring
when we append() to the parser's strand.
On a whim, I set a breakpoint in advance(), start the process over again,
and when the breakpoint fires, I set a hardware watch on p->strand.
(gdb) break advance
Breakpoint 1 at 0x400db0: advance. (2 locations)
(gdb) run
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/jhunt/code/braid/msgtest
<t/test-data/braid.test.cF9n4TI
Breakpoint 1, advance (p=0x7fffffffdd00) at src/msg.c:206
206 if (!p->req)
(gdb) watch p->strand
Hardware watchpoint 2: p->strand
The lovely thing about hardware watch points is that GDB traps all changes to that memory address, and will dump us back into the debugger whenever they occur. For convenience, I cleared my breakpoint (don't need it anymore), and continue on.
(gdb) clear advance
Deleted breakpoint 1
(gdb) continue
Continuing.
... more program output, mostly my annoying printf() debugging ...
Hardware watchpoint 2: p->strand
Old value = (struct strand *) 0x0
New value = (struct strand *) 0x604060
advance (p=0x7fffffffdd00) at src/msg.c:250
250 if (c == end)
Excellent. p->strand changed from 0x0 (no strand) to 0x604060, some
bit of heap-allocated memory. Nothing unusual here; continuing on.
(gdb) continue
Continuing.
... more program output, mostly my annoying printf() debugging ...
Hardware watchpoint 2: p->strand
Old value = (struct strand *) 0x604060
New value = (struct strand *) 0x0
advance (p=0x7fffffffdd00) at src/msg.c:254
254 c += 1;
This is just the parser weaving the strands back together into a string and disposing of the (now unneeded) strands. Perfectly normal. GDB and I continue in this vein for a while, back and forth, NULL → !NULL, !NULL → NULL until a very curious thing happens.
(gdb) continue
Continuing.
and we're out of bytes. sliding the buffer.
Hardware watchpoint 2: p->strand
Old value = (struct strand *) 0x604060
New value = (struct strand *) 0x604000
advance (p=0x7fffffffdd00) at src/msg.c:224
224 end = p->buf + p->used;
Weird. The "and were out of bytes..." bit is the program indicating that it
hit the end of the fixed-size read buffer, and is about to append to the
strand. Normally, appending to the strand leaves p->strand alone (append
happens at the end, modifying the terminus ->next pointer). But here,
we've ... we've assigned an interesting value to the strand pointer.
It's exactly 96 bytes before the value it used to have.
That's weird for a variety of reasons. For starters, heap allocation
usually works from lower to higher memory addresses as it chugs through the
arena or the slab (depending on the allocator). Also, 96 bytes doesn't seem
to match the sizeof() any of my structures (I checked).
On a whim (and perhaps to keep my fingers busy while my brain idled), I ran:
(gdb) list 224
219 p->used += nread;
220 if (p->used == 0)
221 return -1;
222 p->buf[p->used] = '\0';
223
224 end = p->buf + p->used;
225 c = p->buf + p->dot;
226
227 again:
228 switch (p->state) {
And stared at the output for a good five minutes. Realization dawns on me
slowly, as I then decide to look at the parser structure itself, *p:
(gdb) print *p
$3 = {flags = 0, dot = 0, used = 1024, fd = 0,
buf = 'A' <repeats 1024 times>, strand = 0x604000,
state = 6, req = 0x604010, header = 0x604120}
Everything clicks into place. The devious machinations and lewd gyrations this execution path has made come to the forefront of my mind. I dare say I heard a choir of angels sing out in a Hallelujah! of buffer overruniness.
See p->buf is the fixed-size buffer window. It's right next to
p->strand in the memory layout, and because it's a nice round number
(1024, 4096, 8192, all of them nice round numbers), there's no structure
padding to maintain alignment.
The memory looks something like this:
|.----- buf -----.|.--------- strand --------.|
+---+---+-----+---+------+------+------+------+
| A | A | ... | A | 0x60 | 0x40 | 0x60 | 0x00 |
+---+---+-----+---+------+------+------+------+
Since this is an x86-64 chip, everything is little-endian, so 0x604060
(the previous value of p->strand is stored least-significant byte first,
or 60 40 60 00.
Refer back to the last code listing we did. Notice that line 222 explicitly
sets the p->used'th cell of p->buf to \0, which is a fancy string-like
way of writing 0x00.
So we go from:
|.----- buf -----.|.--------- strand --------.|
+---+---+-----+---+------+------+------+------+
| A | A | ... | A | 0x60 | 0x40 | 0x60 | 0x00 |
+---+---+-----+---+------+------+------+------+to:
|.----- buf -----.|.--------- strand --------.|
+---+---+-----+---+------+------+------+------+
| A | A | ... | A | 0x00 | 0x40 | 0x60 | 0x00 |
+---+---+-----+---+------+------+------+------+overwriting the least significant byte of our strand pointer. The next time
we try to deal with the strand, we're going to fall short of 0x604060, and
land in 0x604000, thanks to that misplaced NULL terminator.
Once I figured that out, I did a little bit of digging, scanning back up through the code listing:
(gdb) list 217
212 nread = read(p->fd,
213 p->buf + p->used,
214 PBUFSIZ - p->used);
215
216 if (nread < 0)
217 return -1;
218
219 p->used += nread;
220 if (p->used == 0)
221 return -1;
Sure enough, there's the culprit. When we read() into the buffer, we
fill it completely, using up every ounce of space. Then we advanced
p->used forward, exactly the number of bytes we read. If there's more
to be read than buffer space, p->used will EQUAL PBUFSIZ, which means
that line 222 tries to assign the terminator beyond the end of the buffer.
(Admittedly this is why people discourage implementing much of anything in C. Personally, I live for this stuff.)
Mystery solved. A well-meaning bit of code to properly NULL-terminate a string buffer (probably for debugging or something) ran afoul of assumptions of previous code, and ended up munging a nearby pointer that was minding its own business.
Were it not for those hardware watch points in GDB, and Valgrind pointing to possible memory corruption, this bug could have entailed an excruciating line-by-line review of the codebase.
Happy Hacking!

James works on the Internet, spends his weekends developing new and interesting bits of software and his nights trying to make sense of research papers.
Currently exploring just how much data you can shove though DuckDB before it explodes.